本篇文章為翻譯文章,原文資訊如下:
原文網址:Ceph剖析:数据分布之CRUSH算法与一致性Hash
原文作者:吳香偉
將資料分散儲存是分散式儲存的一個重要議題,而將資料分散的演算法至少要考慮以下三個因素:
- 故障與隔離:相同資料的不同副本應分散在不同的故障區域,以降低資料損壞的風險。
- 負載平衡:資料要能夠平均分散在硬碟容量不同的儲存節點,避免部分節點硬碟空間剩餘過多;而部分節點硬碟空間不足甚至超載,進而影響系統效能。
- 新增/刪除節點時,所造成的資料搬移:當刪除節點時,最好的資料搬移是只有將離線節點上的資料搬移至其它節點,而其餘節點的資料不會發生搬移。
物件儲存(Object Store)中的一致性 Hash與 Ceph 的CRUSH是比較常見的資料分散演算法。而在 Amazon 的 Dynamo 的 key-value 儲存系統中使用了一致性 Hash,並且對其做了很多優化;OpenStack 的 Swift 物件儲存系統亦使用了一致性 Hash。
一致性 Hash
假設資料為 x,儲存節點數量為 N。將資料分散至儲存節點中,最簡單的方法是:
- 計算資料 x 的 hash 值;
- 將 hash(x) % N,其結果即為將資料 x 儲存至節點 N。
而資料經過 Hash 的目的是為了可以讓資料平均分散在 N 個節點中,但這種做法有一個嚴重的問題,就是當加入或刪除節點時,幾乎所有資料都會受到影響,需要重新分配,因此,其資料的搬移量是非常大的。
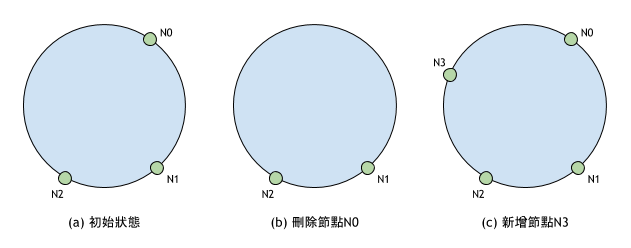
如上圖所示,一致性 Hash將資料和儲存節點映射到同個 Hash 空間。Hash 環中的 3 個儲存節點把 Hash 空間分為 3 個區段,每個儲存節點負責一個區段上的資料,例如:區段 [N2, N0] 上的資料儲存在節點N0。
一致性 Hash能夠很好的控制節點的新增與刪除所導致的資料搬移的搬移量。
- 刪除節點
如上圖(b)所示,當節點N0刪除時,原本由它負責的 [N2, N0] 區段與 [N0, N1] 區段合併成為 [N2, N1] 區段,並且都由節點N1負責。也就是說本來儲存在節點N0上的資料都搬移至節點N1,而原本儲存在N1與N2節點上的資料不受影響。 - 新增節點
如上圖(c)所示,當節點N3加入時,原本 [N2, N0] 區段分為 [N3, N0] 與 [N2, N3] 兩個區段,其中 [N3, N0] 區段上的資料搬移到新加入的節點N3。
虛擬節點
一致性 Hash的一個問題是,儲存節點不能將 Hash 空間平均的劃分。如下圖(a)所示,區段 [N2, N0] 的大小幾乎是其他區段大小之和,這容易讓負責該區段的節點N0負載過重。假設 3 個節點的硬碟容器相等,那麼當節點N0的硬碟容量已經寫滿資料時,其他兩個節點上的硬碟還有很大的空間,但此時系統已經無法繼續向區段 [N2, N0] 寫入資料,而造成資源的浪費。
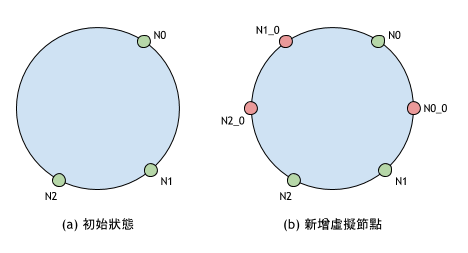
虛擬節點是相對於實體節點,虛擬節點負責的區段上的資料,最終儲存到其對應的實體節點。在一致性 Hash中引入虛擬節點可以把 Hash 空間劃分成更多區段,讓資料能更平均的分散在儲存節點上。如上圖(b)所示,紅色的節點代表虛擬節點,Ni_0 代表該虛擬節點對應於實體節點 i 的第 0 個虛擬節點。增加虛擬節點後:
- 實體節點
N0負責 [N0, N1_0] 與 [N2_0, N1_0] 兩個區段; - 實體節點
N1負責 [N0_0, N1] 與 [N0, N0_0] 兩個區段; - 實體節點
N2負責 [N2, N1] 與 [N2_0, N2] 兩個區段。
因此,三個物理節點負責的資量量趨於平均。
而在實際應用中,可以依據實體節點的硬碟大小來確定其對應的虛擬節點數量。虛擬節點數量越多,節點負責的資料區段也越大。
區段與區段位置
先前提到,當節點加入或刪除時,區段會進行分裂或合併,這不對新寫入的資料構成影響,但對於已經寫入到硬碟的資料需要重新計算 Hash 值以確定它是否需要搬移到其他節點,因為需要查詢整個硬碟中的所有資料,這個計算過程非常耗時。
如下圖(a)所示,區段是由落在 Hash 還上的虛擬節點 Ti 來劃分的,並且區段位置(儲存區段資料的節點)也同虛擬節點相關,及儲存到其順時針方向的第 1 個虛擬節點。
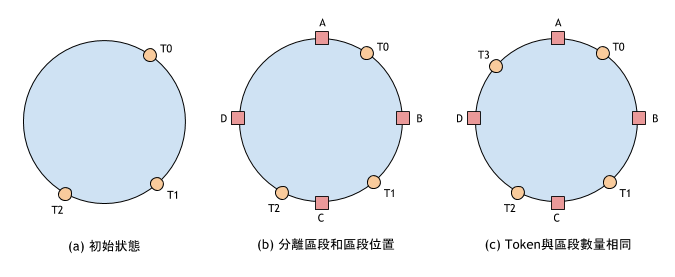
在 Dynamo 的論文中提出了分離區段和區段位置的方法來解決這個問題。該方法將 Hash 空間分為固定的若干區段,虛擬節點不再用於劃分區段,而用來確定區段的儲存位置。如上圖(b)所示,將 Hash 空間劃分成 [A, B]、[B, C]、[C, D]、[D, A] 四個固定的區段。虛擬節點用於確定區段位置,例如:T1 負責區段 [B, C];T2 負責區段 [C, D];T0 負責區段 [D, A] 和 [A, B] 兩個區段。由於區段固定,因此搬移資料時,可以很容易知道哪些資料需要搬移;哪些資料不需要搬移。
上圖(b)中虛擬節點T0負責了 [D, A] 和 [A, B] 兩個區段的資料,這是由於區段數量與虛擬節點數量不同導致的。而為了讓區段分佈得更加平均,Dynamo 提出了區段數量和虛擬節點數量相等的方法,這樣每個虛擬節點負責一個區段,在實體節點的硬碟容量相同並且虛擬節點數量相同的情況下,每個實體節點負責的區段大小是完全相同的,進而達到最佳的資料分散。
CRUSH 演算法
Ceph 分散資料的過程:
- 計算資料 x 的 hash 值;
- 將 hash(x) % PG數量,其結果即為將資料 x 儲存至的 pg 編號;
- 然後,透過
CRUSH將 PG 映射到一組 OSD 中; - 最後,把資料 x 儲存至 PG 對應的 OSD 中。
這個過程中包含了兩次映射,第一次是資料 x 到 PG 的映射,若把 pg 當作儲存節點,那麼這雨先前提到的一般 Hash 演算法一樣,但 pg 是抽象的儲存節點,它不會隨著實體節點的新增或刪除而增加或減少,因此資料到 pg 的映射是穩定的。
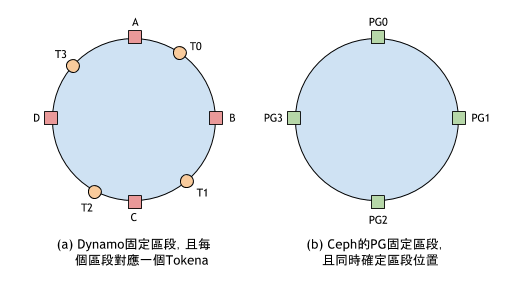
在這個過程中,PG 擁有兩個作用:
- 劃分資料區段:每個 PG 管理的資料區段大小相同,因此資料能更平均的分散至 PG 上。
- 充當 Dynamo 中 Token 的角色,即決定區段位置:實際上,這和 Dynamo 中固定區段數量以及維持區段數量和虛擬機節點數量相等的原則是一樣的概念。
在沒有多副本的情況下,Dynamo 中區段的資料直接儲存到 Token,而每個 Token 對應唯一的一個實體儲存節點。而在多副本(假設副本數為 N)的情況下,區段的資料會儲存至連續的 N 個 Token 之中,而這衍生了一個新的問題:因為副本必須保持在不同的實體節點上,但這組 Token 中存在兩個或多個 Token 對應到同一個實體儲存節點,那勢必要跳過這樣的節點。而 Dynamo 使用 Preference 列表來紀錄每個區段對應的實體節點,且論文中沒有詳述區段的 Preference 列表如何選擇實體節點與選擇實體節點時,該如何隔離故障區域等問題。
(osd0, osd1, osd2 … osdn) = CRUSH(x) |
Ceph 的 PG 擔任起 Dynamo 中 Token、固定區段與 Preference 列表的角色,解決了同樣的問題。PG 的 Acting 集合等同於 Preference 列表,CRUSH解決了 Dynamo 論文中未提及的問題。
OSD 階層架構和權重大小
CRUSH的目的是:
為給定的 PG(即區段)分配一組儲存資料的 OSD 節點
而選擇 OSD 節點的過程,要考慮以下幾個因素:
- PG 在 OSD 間平均分散:假設每個 OSD 的硬碟大小皆相同,那麼我們希望 PG 在每個 OSD 節點上是平均分散的,也就是說每個 OSD 節點包含相同數量的 PG。假如節點的硬碟容量不等,那麼硬碟容量大的節點能夠處理更多數量的 PG。
- PG 的 OSD 分佈在不同的故障域:因為 PG 的 OSD 列表用於保存資料在不同的副本,副本分佈在不同的 OSD 中可以降低資料損壞的風險。
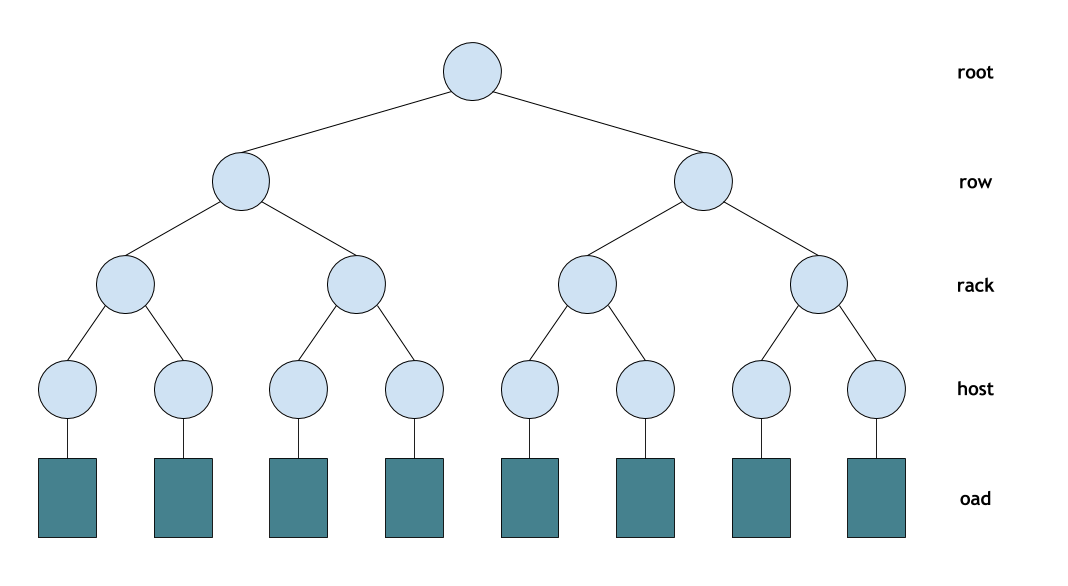
Ceph 使用樹型階層架構描述 OS 的空間位置與權重大小。如上圖所示,階層架構描述了 OSD 所在主機、主機所在機架與機架所在的機房等空間位置。這些空間位置隱含了故障區域,例如:使用不同電源的不同機架屬於不同故障區域。CRUSH能夠依據一定的規則將副本放置在不同的故障區域。
OSD 節點在階層架構中也被稱為Device,它位於階層架構的葉節點,所有非葉節點的稱為Bucket。而 Bucket 擁有不同的類型,如上圖所示,所有機架的類型為 Rack;所有主機的類型為 Host,使用者可以自行定義 Bucket 的類型。Device 節點的權重代表儲存節點的效能,而硬碟容量大小是影響權重大小的重要參數。Bucket 節點的權重是其子結點的權重和。
OSD weight = OSD size / 1 TB
CRUSH 透過重複執行Take(bucketID)和Select(n, bucketType)兩個操作選擇副本位置。兩個操作說明如下:
Take(bucketID)指定從給定的 bucketID 中選擇副本位置,例如:可以指定從某台機架上選擇副本位置,以實現將不同的副本隔離在不同的故障域;Select(n, bucketType)則在給定的 Bucket 下選擇 n 個類型為 bucketType 的 Bucket,它選擇的 Bucket 主要考慮階層架構中節點的容量以及當節點新增或刪除時的資料搬移量。
算法流程
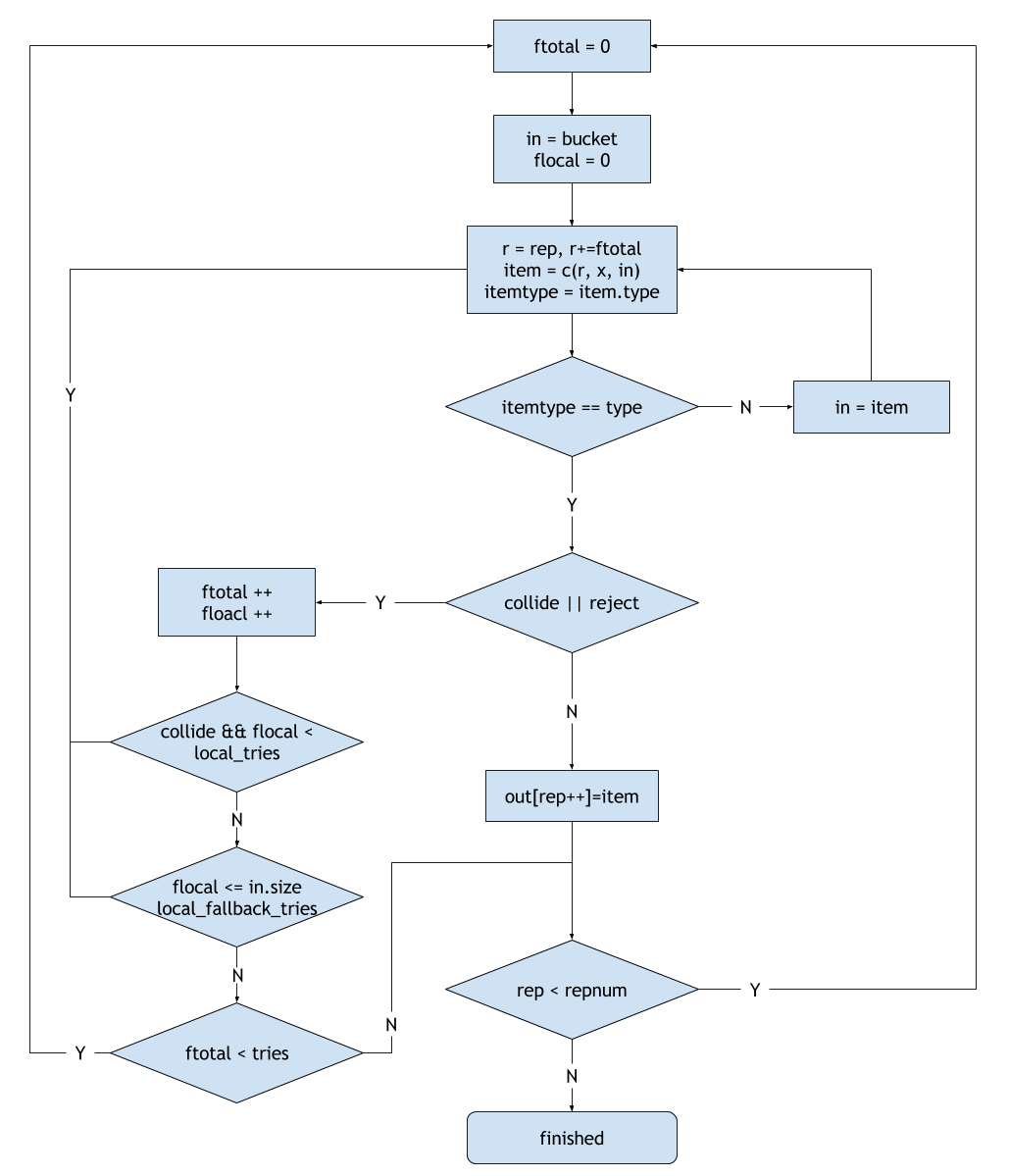
如上圖所示,為CRUSH選取副本的流程圖。其符號表示如下:
- bucket:
Take操作指定的bucket; - type:
Select操作指定的 Bucket 類型; - repnum:
Select操作指定的副本數量; - rep:當前選擇的副本編號;
- x:當前選擇的 PG 編號;
- item Bucket:代表當前被選中的 Bucket;
- c(r, x, in):代表從 Bucket in 中,為 PG x 選取第 r 個副本;
- coolide:代表當前選中的副本位置 item 已經被選中,即出現衝突;
- reject:代表當前選中的副本位置 item 被拒絕,例如:item 已經處於 out 狀態的情況下;
- ftotal:在 Descent 區域中選擇的失敗次數,即選擇一個副本位置的總共的失敗次數;
- flocal:在 Local 區域中選擇的失敗次數;
- local_tries:在 Local 區域選擇衝突時的嘗試次數;
- local_fallback_tries:允許在 Local 區域的總共嘗試次數為 bucket.size + local_fallback_retries 次數,以保證遍歷完 Bucket 的所有子結點;
- total_tries:在 Descent 的最大嘗試次數,超過這個次數則放棄這個副本。
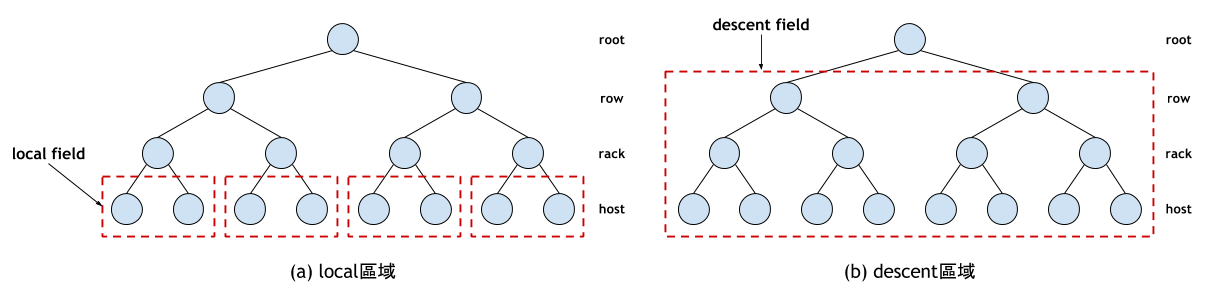
如上圖所示,當Take操作指定的 Bucket 和Select操作指定的 Bucket 類型之間隔著幾層的 Bucket 時,CRUSH會直接深度優先地進入到目的 Bucket 的直接父母節點。例如:從跟節點開始選擇 N 個 Host 時,它會深度優先地找到 Rack 類型的節點,並在這個節點下選取 Host 節點。為了方便描述,將 Rack 的所有子節點標記為 Local 區域;將 Take 指定的 Bucket 子結點標記為 Descent 區域。
選取過程中發生衝突、過載或者故障時,CRUSH會先在 Local 區域內重新選擇,嘗試有限次數後,如果仍然找不到滿足條件的 Bucket,那就回到 Descent 區域重新選擇。而每次重新選擇時,修改副本數目r += ftotal,所以每次選擇失敗都會遞增ftotal,因此可以盡量避免選擇時再次選到衝突的節點。